
La información es poder ,¿ es solamente un dicho?.
La respuesta dependerá de donde usted almacena toda la información que necesita, como está organizada y de que forma lpuede hacerla disponible a las distintas personas, empresas etc..
La necesidad de mejorar la manera de acceder y manejar los datos ha evolucionado desde el concepto de IMS (Information Management System) a la nueva generación de sistemas de administración de bases de datos relacionales (RDBMS).
En los últimos tiempos usted ha escuchado hablar sobre una nueva base de datos, llamada Universal , que puede almacenar y hacer búsquedas no solamente de datos alfanuméricos sino también de imágenes, audio, video y otros objetos.
Esta ventaja de las bases de datos universales abre un sinnúmero de oportunidades que permiten mejorar tanto los servicios como las aplicaciones.
El siguiente ejemplar fue diseñado por los alumnos de la cátedra de Bases de Datos II, correspondiente a la carrera de la Licenciatura en Análisis de Sistemas, ante la escasa documentación que se dispone de la Base de Datos Universal DB2 en español, y con el fin que usted conozca en parte DB2.
El mismo se encuentra orientado como primera medida a presentarle las distintas características de la Base de Datos DB2 y luego con un poco mas en detalle las distintas herramientas que posee y la forma en que se relaciona esta con los datos que almacena.
Por una cuestión de alcance no se desarrolla en esta edición temas técnicos en cuanto a la tecnología, los lenguajes soportados por DB2 , protocolos y en las aplicaciones en las que se utiliza actualmente DB2.
En gran medida la intención fundamental es la de presentar un material que le muestre con un cierto nivel de profundidad las distintas formas en que DB2 administra la gran variedad de datos que maneja y conozca las ventajas de las mismas.
Esperando que este satisfaga las expectativas le dejamos en sus manos el siguiente ejemplar quedando a su disposición para consultas o ampliaciones que desee sobre DB2 en particular. De igual forma el mismo se irá actualizando en INTERNET y podrá disponer de las nuevas características que se presenten en un futuro inmediato.
Grandes
razones para elegir DB2 Universal Database

Fácil
y simple
Muchos
expertos de la industria y usuarios han
elogiado las nuevas herramientas que IBM desarrolló para facilitar
la administración y uso del DB2 Universal Database. Utiliza una
interfase gráfica, estilo browser, para acceder y manejar objetos
de la base de datos. Incluye smart.guides que facilitan la tarea de
configuración, guiándolo paso a paso para lograr un rendimiento
óptimo de la base de datos y para asistir al usuario en la creación
de teclas con plantillas predefinidas. Las herramientas mencionadas, más
otras incluidas en DB2 Universal Database, están listas para ser
integradas a Tivoli.
Aplicaciones existentes
Más
del 70% de las empresas top del mundo confían en DB2 Universal Database
para manejar aplicaciones críticas. Si su empresa es una de ellas,
usted puede aprovechar su conocimiento para poner en funcionamiento todas
estas aplicaciones de negocios:
-
On-line
Transaction Processing (OLTP)
-
Data
Warehousing
-
Decision
Support
-
Data
Mining
Soporte
OLAP

DB2
Universal Database ofrece nuevas capacidades para ayudarlo a realizar análisis
multidimensional y procesamiento analítico en línea (OLAP).
Incluye funciones de ROLLUP, CUBE y grouping sets. Soporta
STAR JOINS. Estas facilidades
son utilizadas normalmente en todas las aplicaciones de business intelligence.
Lista
para Internet
Gracias
a su alcance global y bajo costo, Internet puede ser una solución
de negocios muy poderosa. Si usted quiere realmente aprovechar las oportunidades
de negocios utilizando la Web, considere la mejor manera de llegar a un
mercado que lo está esperando 1as 24 horas de los 7 días
de la semana. La base de datos que seleccione debe estar preparada para
brindar acceso rápido y alta disponibilidad a información
que requiere actualización constante. DB2 Universal Database provee
la capacidad de hacer backups en línea, evitando interrupciones
en la disponibilidad del sistema. Permite realizar operaciones comerciales
garantizando un alto nivel de seguridad y confiabilidad.
DB2
cumple con todos estos requerimientos y mucho más:
-
Soporta
el paradigma de network-computing utilizando Java y JDBC
-
Brinda
excelente nivel de seguridad
-
Net.Data
brinda acceso a sus datos corporativos desde la Web
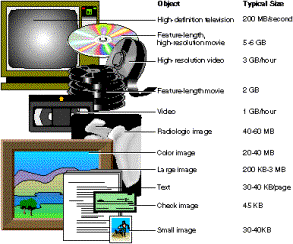
DB2
Universal Database incluye la capacidad nativa de almacenar variados tipos
de datos: alfanuméricos, video, imagen, audio y los que usted defina.
Algunas alternativas, a veces más caras, solamente proveen una capacidad
incompleta y una integración limitada. Otra gran diferencia: la
escalabilidad de DB2 Universal
Database permite el almacenamiento de grandes volúmenes de datos
aprovechando al máximo la capacidad de las plataformas soportadas
por DB2. Aunque no esté utilizando aplicaciones avanzadas basadas
en multimedia, lo invitarnos a analizar los beneficios. Estos lo ayudarán
a minimizar los costos y tiempos relacionados con el manejo usual de la
documentación que fluye en su empresa. DB2 Universal Database permite
realizar búsquedas sofisticadas e inteligentes en cualquier documento
utilizando innumerables criterios.
Además,
permite que el usuario defina funciones -llamadas UDFs- y tipos de datos
propios -llamados UDTs. Estos facilitan enormemente la tarea de administración
de datos por parte de los desarrolladores, asegurando la consistencia de
los mismos y minimizando los errores por operaciones inválidas.
Formida
Software Corp. ha desarrollado una solución para la industria de
la salud, que incluye las capacidades multimedia de DB2 Universal Database.
La aplicación maneja datos complejos, tales como: imágenes
de rayos X, gráficos, video, mapas para la localización de
médicos y hospitales, además de archivos de historias clínicas
e información de seguros.
Introducción

DB2
UNIVERSAL DATABASE ( DB2 UDB )
DB2 (R) Universal Database, es una base de datos universal. Es completamente escalable, veloz y confiable. Corre en modo nativo en casi todas las plataformas, como Windows NT (R), Sun Solaris, HP-UX, AIX(R), OS/400 y OS/2(R).
Características y funciones:
DB2 UDB es el producto principal de la estrategia de Data Management de IBM.
DB2 UDB es un sistema para administración de bases de datos relacionales (RDBMS) multiplataforma, especialmente diseñada para ambientes distribuidos, permitiendo que los usuarios locales compartan información con los recursos centrales.
Historia
:
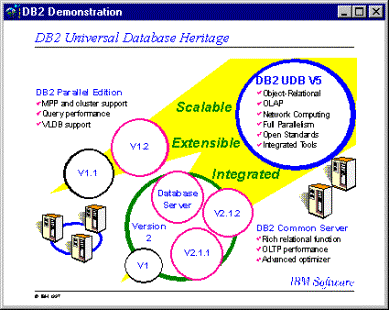
DB2 UDB no es un producto nuevo. Fue construido en base a dos productos incluidos en el DB2 de AIX en el año 1994: DB2 Common Server, que para propósitos generales incluía funciones avanzadas para el mercado de servidores de bases de datos, con soporte de hardware SMP y OLTP; y el DB2 Parallel Edition, que fue desarrollado para soportar aplicaciones de gran escala, como Data Warehousing y Data Mining.
Integridad
:
DB2 UDB incluye características de integridad, asegurando la protección de sus datos aún en caso de que los sistemas sufran un colapso; y de seguridad, permitiendo realizar respaldos en línea con distintos grados de granularidad, sin que esto afecte la disponibilidad de acceso a los datos por parte de los usuarios.
Múltiples
usos :
Provee la capacidad de hacer frente a múltiples necesidades, desde procesamiento transaccional de misión crítica (OLTP), hasta análisis exhaustivo de los datos para el soporte a la toma de decisiones (OLAP).
Escalabilidad
:
Sus características distintivas de escalabilidad le permiten almacenar información en un amplio rango de equipos, desde una PC portátil hasta un complejo ambiente de mainframes procesando en paralelo.
Web
enabled
para
E-business :
Incluye tecnología basada en Web que permite generar aplicaciones en sus Intranets y responder a las oportunidades de negocios disponibles en Internet. Además, DB2 UDB provee soporte a Java.
Facilidad
de instalación y uso :
La primera versión de DB2 para NT fue reconocida en el mercado como una base de datos muy poderosa, pero difícil de instalar y usar. En esta versión (DB2 UDB), IBM agregó muchas herramientas gráficas para facilitar el uso tanto de usuarios, como administradores y desarrolladores. Incluye guías para operaciones como instalación, configuración de performance, setup, etc. Además, se agregaron herramientas para facilitar las tareas de integración con otras bases de datos, tecnologías de networking y desarrollo de aplicaciones.
Universalidad
:
DB2 UDB es, además, la única base de datos realmente universal: es multiplataforma (16 plataformas - 10 no IBM), brinda soporte a un amplio rango de clientes, soporta el acceso de los datos desde Internet y permite almacenar todo tipo de datos incluyendo texto, audio, imágenes y video o cualquier otro definido por el usuario.
Funciones
complementarias
Conectividad
Las herramientas de conectividad permiten acceder a los datos más allá de donde ellos se encuentren. El slogan 'cualquier cliente, a cualquier servidor, en cualquier red' está completamente sustentado por la funcionalidad que sus herramientas ofrecen. EL DB2 Connect le permiten acceder a sus datos de DB2 en mainframe o AS/400, desde Windows NT, Windows 95 / 98, OS/2 o cualquiera de los Unix soportados. Además, el producto Datajoiner posibilita acceder de forma única y transparente a los datos residentes en Oracle, Sybase, Informix, Microsoft SQL Server, IMS, VSAM y otros.
Data
Warehousing
DB2 UDB provee la infraestructura necesaria para soportar el proceso de toma de decisiones en cualquier tamaño y tipo de organización. Es el producto dirigido a resolver la problemática a nivel departamental (Data Marts), ya que un único producto provee la capacidad para acceder a datos en Oracle, Sybase, Informix, Microsoft SQL Server, VSAM o IMS, además de la familia DB2. Permite de forma totalmente gráfica acceder, transformar y distribuir los datos automáticamente y sin programar una línea de código.
Data
Mining
DB2 UDB posibilita el análisis orientado al descubrimiento de información escondida en los datos, realizando modelización predictiva, segmentación de la base de datos, análisis de vínculos, o detección de desviaciones. Incluye las siguientes técnicas: clustering (segmentación), clasificación, predicción, descubrimiento asociativo, descubrimiento secuencial de patrones y secuencias temporales. Todas las técnicas mencionadas permiten realizar segmentación de clientes, detección de fraudes, retención de clientes, ventas cruzadas, etc.
Integridad
Referencial

Restricciones
Restricciones
preferenciales
Conceptos
Clave
Maestra:
Una
tabla es descendente de una tabla T, si esta es dependiente de T.
RULE-INSERT (Regla
de inserción)
- RESTRICT or NO ACTION; ocurre un error y las filas no son eliminadas.
- CASCADE; La operación de eliminación se propaga de la fila dependiente p a D.
- SET NULL; cada valor que es factible de anular en la columna correspondiente a la clave foránea de la tabla D es puesto como NULO.
- Si la tabla D que es dependiente entre P y la regla es RESTRICT or NO ACTION, D está involucrada en la operación, pero no es afectado por la operación.
- Si la tabla D, que depende de P y la regla es SET NULL, D está involucrada en la operación, y las filas D pueden actualizarse durante la operación.
- Si la tabla D, es dependiente de P y la regla de eliminación se indica como CASCADE, D esta incluida en la operación y las filas de D pueden eliminarse durante la operación.
- Si las filas D son eliminadas, la operación de eliminado en P se dice que se extendió a D. Si D, también es una tabla Padre, las acciones descriptas en esta lista, a su vez, se aplican a los dependientes de D.
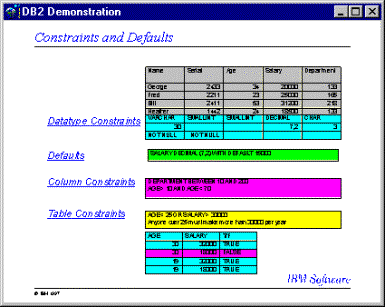
Hay
tres tipos de restricciones:
Una
restricción única o unique constraint es
un modelo que excluye valores duplicados en uno o más columnas dentro
de una tabla. Unique y clave primaria son los soportes de singular constraints.
Por ejemplo, un singular constraint puede ser definido sobre el identificador
proveedor (supplier identifier) dentro de la tabla proveedora (supplier
table) para garantizar que el mismo identificador proveedor (suppler identifier)
no esta siendo dado a dos proveedores.
Una
restricción referencial o referential constraint es
una norma lógica sobre los valores en una o mas columnas y en una
o más tablas. Por ejemplo, un conjunto de tablas comparten información
sobre proveedores de una corporación.
De
vez en cuando, el nombre de un proveedor cambia. Una restricción
referencial (Referential constraint) puede ser definido declarando que
él ID del proveedor en la tabla debe estar unido a un proveedor
ID en la información del proveedor. Este constraint previene de
inserciones, modificaciones o eliminaciones que permitan de otra manera
resultar en perdida de información de proveedores. (supplier information).
Una
tabla de control de restricciones table check constraint
establece restricciones en la inserción de datos a una tabla especifica.
Por ejemplo, se puede definir el nivel de salario para un empleado que
nunca debe ser menor que $ 20.000 cuando el salario es agregado o modificado
en la tabla que contiene la información personal.
Referential y
table check constraints pueden ser cambiados a on u off. Cargando una
larga cantidad de datos dentro de la base de datos en un momento típico
para cambiar a off la verificación de
la puesta en marcha de una restricción.
Restricción
Única
Un
unique constraint es la regla que permite que un solo valor de la
clave sea válido en una tabla .
Unique
constraints
es opcional y puede ser definida en el create table o alter table
usando la opción de clave primaria o la opción de unique.
La columna especificada en un unique constraint debe ser definida
como no nula. El unique index es usado por el administrador de base
de datos para reforzar la unicidad de la clave durante los cambios a la
columna de la unique constraint.
La
tabla puede tener números arbitrarios de restricción únicas,
con mas de una restricción única definida como clave
primaria. La tabla puede no tener mas que una restricción única
en el mismo set de columnas.
La
restricción única que es referenciada como una clave
foránea de una referential constraint es llamada como clave
pariente.
Cuando
una restricción única es definida en la opción
create table, un unique index es automáticamente creado
por el administrador de base de datos y designado como primary or unique
system-required index.
Cuando
la restricción única es definida en el opción alter
table y un indexado existe en la misma columna, ese indexado es designado
como unique and system.requied. Si tal indexado no existe, el unique index
es automáticamente creado por el administrador de base da datos
y designado como primary or unique system-required index.
Note
que existe una diferencia entre definir una restricción única
y crear un único índice.
Tabla
de Control de Restricciones
(Table Check Constraints)
Una
Table check constraints es una norma que especifica el valor permitido
en una o más columnas de cada fila de una tabla. Son opcionales
y pueden ser definidas usando la sentencia SQL create table y
alter table. La especificación de table check constraints
es un formulario de restricciones de una condición de búsqueda.
Una de las restricciones es que el nombre de la columna en la table check
constraint de la tabla T debe identificar a la columna de T.
La
tabla puede tener un numero arbitrario de table check constraints. Son
forzadas cuando:
Funciones
Incorporadas
Funciones
Aritméticas
Existen
algunas funciones mas que manejan texto. Note que estas son algunos ejemplos
de las funciones que están disponibles
VALUES
('REPEAT("*",5) ',REPEAT('*',5)),
('LTRIM(" *") ',LTRIM(' *')),
('LCASE("ABCDEF") ',LCASE('ABCDEF')),
('REPLACE("x1x1x","1","2")
',REPLACE('x1x1x','1','2')),
('MONTHNAME(CURRENT
DATE),MONTHNAME (CURRENT DATE
('DAYNAME(CURRENT
DATE) ',DAYNAME(CURRENT DATE))
Funciones
Soundex
Las
funciones soundex toman como un argumento un string de caracteres o retorna
un valor de 4-bytes que representan el sonido del string. Por supuesto,
esta función es altamente dependiente del idioma ingles, por lo
tanto puede no ser necesariamente el retorno correcto en otro idioma. Sin
embargo, una función como esta es muy utilizada cuando esta intentando
encontrar un valor que suene como algo. El siguiente ejemplo lista todos
los empleados de la compañía que tengan nombres que suenen
similares.
SELECT
A.LASTNAME, B.LASTNAME
FROM
EMPLOYEE A, EMPLOYEE B
WHERE
SOUNDEX(A.LASTNAME) = SOUNDEX(B.LASTNAME)
AND
A.LASTNAME <> B.LASTNAME
Funciones
Soundex (2° ejemplo)
En
este ejemplo de Soundex, se esta buscando gente de la compania que tengan
un apellido que suene parecido al SMITH
SELECT
LASTNAME FROM EMPLOYEE
WHERE
SOUNDEX(LASTNAME) = SOUNDEX('SMITH')
Funciones
definidas por el usuario

Las funciones definidas por
el usuario son extensiones a lo que ya esta creado en las funciones del
lenguaje SQL. Las funciones creadas por el usuario pueden ser:
-Función
escalar, la cual devuelve un valor cada vez que se la invoca
-Función
columna, donde se pasa un conjunto de valores y devuelve un valor único
para el conjunto
-Función tabla, que devuelve una tabla
Una función definida por el usuario del tipo escalar o en columna registrada en la base de datos puede ser referenciada en el mismo contexto que cualquier función predefinida
Una función definida por el usuario del tipo de tabla registrada en la base de datos puede ser referenciada solo en el FROM de la cláusula SELECT
Una función definida por el usuario se invoca con su nombre, seguido de los argumentos entre paréntesis (if any)
Los argumentos de la función deben corresponder en numero y posición con los parámetros especificados en la función definida por el usuario como fueron registrados en la base de datos. En resumen, los argumentos deben ser del tipo de datos correspondientes a los parámetros definidos.
El resultado de la función es, como en la cláusula RETURN, especificado cuando la función definida por el usuario fue registrada. La cláusula RETURN determina si una función es del tipo tabla o no.
Si la cláusula NOT NULL
CALL fue especificada (o esta por defecto) cuando la función fue
registrada, y si algún argumento es nulo, entonces el resultado
es nulo. Para las funciones del tipo tabla, esto significa el retorno de
una tabla sin registros (tabla vacía).
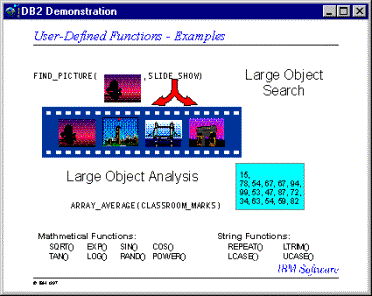
Ejemplos:
Supongamos que una función escalar llamada ADDRESS fue escrita para extraer la dirección de un formato de script. La función ADDRESS recibe un argumento CLOB y devuelve un VARCHAR(4000). El siguiente ejemplo muestra la llamada a la función ADDRESS
SELECT
EMPNO, ADDRESS(RESUME) FROM EMP_RESUME
WHERE
RESUME_FORMAT = 'SCRIPT'
Supongamos que tenemos una tabla T2 con una columna numérica A y la función ADDRESS del ejemplo anterior. El siguiente ejemplo demuestra la intención de invocar a la función ADDRESS con un argumento incorrecto.
SELECT
ADDRESS(A) FROM T2
Un error (SQLSTATE 42884) aparece porque no hay una función con el mismo nombre y con un parámetro correcto desde el argumento.
Supongamos que una función del tipo tabla WHO fue escrita para devolver información sobre las sesiones en la maquina del servidor que estaban activas en el momento de la ejecución. El siguiente ejemplo muestra la llamada de WHO en una cláusula FROM.
SELECT
ID, START_DATE, ORIG_MACHINE
FROM
TABLE( WHO() ) AS QQ
WHERE
START_DATE LIKE 'MAY%'
Los
nombres de columna de la tabla WHO() están definidos en el estado
de CREAR FUNCION
Una función de tabla es una UDF externa la cual entrega en una tabla del SQL en la cual ese es referenciado. Una tabla de función referenciada es solo valida en una cláusula FROM de un SELECT. Donde usando la tabla de funciones, se observa lo siguiente:
Aun cuando una tabla de función entrega una tabla, la interfase física entre el DB2 y la UDF es one-row-at-a-time (una fila a la vez). Hay tres tipos de formas de llamar una tabla de función: OPEN, FETCH y CLOSE. El mismo mecanismo call-type que puede ser usado para funciones escalares es usado para distinguir estos llamados.
La
interfase estándar usada entre DB2 y las funciones escalares definidas
por usuarios se extiende hasta acomodarse en la tabla de funciones. El
SQL-result se repite por tabla de función, en cualquier instancia
correspondiendo a una columna que puede ser retornada con lo que definimos
una cláusula RETURNS TABLE de la CREATE FUNCTION. El argumento SQL-result-ind
asimismo se repite, cualquiera de las instancias relatadas se corresponden
con la instancia SQL-result.
No todos los resultados de las columnas definidas en la cláusula RETURN de la CREATE FUNCTION de la tabla de función tienen que ser retornadas. La clave DBINFO de CREATE FUNCTION, y correspondiendo al argumento habilitado dbinfo, la optimización que solo estas columnas necesitan para una tabla en particular referenciada ser retornada.
Los
valores de las columnas individuales retornadas conformen con el formato
a los valores retornados para funciones escalares.
La
CREATE FUNCTION para una tabla de función tiene una CARDINALITY
n especifica. Esta especificación se define para informar al optimizador
del DB2 del tamaño aproximado del resultado de modo que el optimizador
pueda tomar mejores decisiones cuando la función es referenciada.
Anidar
o Establecer Tablas de Expresión
Tablas
de Expresión
Tablas
de Expresión Común
WHERE
EDLEVEL > :hv1
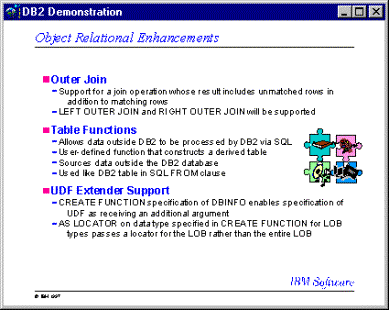
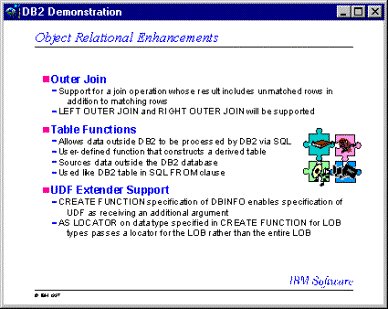
Es
un tipo de consulta en donde aparecen todos los datos de las tablas aunque
no estén cumpliendo las condiciones de join. Es
diferente del join convencional o inner join pues aparecen las filas no
macheadas con la otra tabla.
Existen 3 tipos de outer join:
- El outer join izquierdo incluyendo las filas de la tabla izquierda que no están macheadas con valores de la tabla derecha. A estas filas se le asigna el valor nulo por la información perdida.
- El outer join derecho incluye filas de la tabla derecha que no estan macheadas con valores de la tabla izquierda. A estas filas se le asigna el valor nulo por la información perdida.
- El outer join completo incluye ambas clases de filas.
- El resultado de T1 INNER JOIN T2 consiste en los pares de filas donde la condición del join es verdadera.
- El resultado de T1 LEFT OUTER JOIN T2 consiste en los pares de filas donde la condición del join es verdadera y por cada fila sin par de T1, la concatenación de esa fila con la fila nula de T2.
- El resultado de T1 RIGHT OUTER JOIN T2 consiste en las filas pares donde la condición del join es verdadera y, por cada fila sin par de T2 la concatenación de esas filas con las filas nulas de T1.
- El resultado de T1 FULL OUTER JOIN T2 consiste en las filas pares y por cada fila sin par de T2, la concatenación de esas filas con las filas nulas de T1, y por cada fila sin par de T1, la concatenación de esas filas con las filas nulas de T2.
TEACHERS
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
COURSES
|
|
|
|
|
|
|
|
|
|
|
Fall
96
|
Math
101
|
Mr.Glenn
|
40
|
|
Fall
96
|
English
280
|
Ms.Redding
|
30
|
|
Fall
96
|
Science
580
|
Ms.Redding
|
33
|
|
Fall
96
|
Physics
405
|
Mrs.Plummer
|
28
|
|
Fall
96
|
Latin
237
|
Mr.Glenn
|
20
|
|
Fall
96
|
German
130
|
Staff
|
31
|
|
Winter
96
|
French
140
|
Ms.
Barnes
|
(null)
|
WHERE
quarter = ´Fall 96´
EXCEPT
ALL
SELECT
subject, enrollment
FROM
innerjoin)
SELECT
name, rank, subject, enrollment
|
|
|
|
|
|
|
|
|
|
|
|
|
40
|
|
|
|
20
|
|
|
|
28
|
|
|
|
30
|
|
|
|
33
|
|
|
(null)
|
(null)
|
|
(null)
|
(null)
|
|
31
|
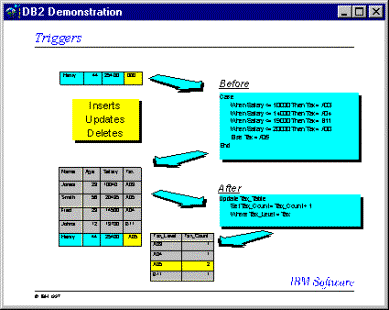
Esta lógica utilizada en todas las tablas implicará un fácil mantenimiento posterior, y que no sea necesario cambiar los programas de aplicación cuando se cambie la lógica de la misma.
Los TRIGGERS son opcionales y se definen mediante la instrucción CREATE TRIGGER .
Hay varios criterios que se deben de tener en cuenta al crear un TRIGGER, que se utilizará para determinar cuando un TRIGGER debe activarse.
- En una tabla se define la tabla que llamaremos objeto para la cual el TRIGGES se utilizará.
- El evento que se ejecutará se lo hace en SQL y esta modificará la tabla. Las operaciones pueden ser: borrar, insertar o actualizar.
- El Triggers activation time define cuando el trigger debe ser activado.
La
activación de in Trigger puede
generar una cascada de Triggers. Esto sucede si el resultado de ejecutar
algún Trigger produce que se active otro o incluso se active a si
mismo.
Distintos
SQL
ORDER
BY SALARY
2. Cláusula
AS
La
cláusula AS se usa cuando se asigna un nombre a un calculo. Puede
ser usada para dar un nombre significativo a un calculo en una columna
de SQL, pero también puede ser usada para evitar errores.
Para
ordenar un calculo, se necesitaba dar el número relativo de la columna
en la cláusula ORDER BY. Ej:
SELECT
SALARIO + COMISION FROM EMPLEADOS ORDER BY 1
Ahora
se puede asignar un nombre a este cálculo y usar este nombre en
el ORDER BY:
SELECT
SALARIO + COMISION AS PAGO FROM EMPLEADOS ORDER BY PAGO
Esto
puede permitir muchos errores en el SQL
SELECT
APELLIDO, SALARIO + PREMIO AS PAGO
FROM
EMPLEADOS
ORDER
BY PAGO
Hardware
Soportado en DB2
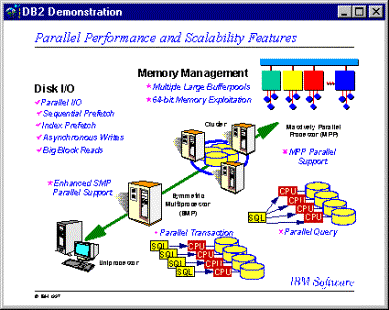
En
esta sección veremos los siguientes entornos de hardware sobre los
cuales funciona DB2 :
- Partición simple sobre un único procesador ( uniprocesador )
- Partición simple con múltiples procesadores ( SMP : Single Partition with Multiple Processors )
- Distintas configuraciones de Partición múltiple :
- Particiones con un procesador ( MPP : Múltiple Partitions with one Processor )
- Particiones con múltiples procesadores ( cluster of SMPs )
- Particiones lógicas de base de datos, también conocidas como Nodos Lógicos Múltiples ( MLN: Multiple Logical Nodes ) en la edición paralela de DB2 para la versión 1 de AIX.
- La Capacidad se refiere al numero de usuarios y aplicaciones accedidas a la base de datos, la cual esta en gran parte determinada por la capacidad de memoria, agentes, locks, entradas-salidas y administración del almacenamiento.
- La Escalabilidad se refiere a la habilidad que posee la base de datos de expandirse y continuar exhibiendo las mismas características operacionales y tiempos de respuesta.
Este entorno se basa en memoria y disco, conteniendo una única CPU.
Este ambiente ha sido denominado de diversas maneras : base de datos aislada
( standalone database ), base de datos cliente/servidor ( client/server
database ), base de datos serial ( serial database ), sistema uniprocesador
( uniprocessor system ), y entorno nodo simple/ no paralelo ( single node/non-parallel
).
La base de datos en este ambiente sirve para cubrir todas las necesidades
de un departamento o de una pequeña oficina de una empresa donde
los datos y los recursos del sistema ( incluyendo un único procesador
o CPU ) son administrados por un único administrador de la base.
Capacidad y Escalabilidad
A este ambiente se le pueden agregar mas discos. Al tener uno o más
servidores de entrada-salida para mas de un disco permite que más
de una operación de entrada-salida ocurra al mismo tiempo.
Un sistema de procesador único esta limitado por la cantidad de
espacio en disco que pueda manejar dicho procesador. Sin embargo, como
la carga de trabajo aumenta, una sola CPU puede llegar a ser insuficiente
para satisfacer las peticiones solicitadas por los usuarios, aun sin importar
cuantos discos y/o memoria adicional hayan sido agregados.
Si se ha alcanzado la máxima capacidad o escalabilidad, se podría
considerar cambiarse a un sistema de partición única con
múltiples procesadores. A continuación se describe esta configuración.
Partición
Simple con Múltiples Procesadores
Este
entorno se compone de varios procesadores de igual potencia dentro de la
misma máquina, llamándose a este ambiente Sistema Simétrico
Multiprocesador ( symmetric multi-processor o SMP ). Los recursos tales
como espacio de disco y memoria son compartidos. En esta máquina
se encuentran más discos y memoria en comparación a una base
de datos de partición simple, en el ambiente de procesador único.
Este
entorno es de fácil administración, debido a que todo esta
ubicado en una sola maquina y además los discos y memoria
están compartidos.
Con
varios procesadores disponibles, diferentes operaciones de la base de datos
pueden ser completadas significativamente más rápido que
en bases de datos asignadas a un solo procesador. DB2 también puede
dividir el trabajo de una consulta simple entre los procesadores disponibles
para mejorar la velocidad de procesamiento.
Otras operaciones de la base de datos, tales como el resguardo ( backup ) y creación de índices sobre datos existentes pueden también aprovechar la ventaja de trabajar con múltiples procesadores.
Capacidad y Escalabilidad
En este entorno se pueden agregar mas procesadores. Sin embargo, es posible
que los distintos procesadores traten de acceder al mismo dato en el mismo
tiempo, lo cual generara la aparición de limitaciones a medida que
las operaciones de su negocio se incrementen. Con discos y memoria compartidos,
se puede efectivamente compartir todos los datos de la base.
Una
aplicación en un procesador puede estar accediendo un dato al mismo
tiempo que otra aplicación lo hace en otro procesador, causando
así que la segunda aplicación espere para acceder a ese dato.
Se puede incrementar la capacidad de entrada-salida de la partición
de la base de datos asociada a un procesador, así como también
el numero de discos. También se pueden establecer servidores de
entrada-salida para repartir las solicitudes de entrada-salida. Al tener
uno o mas servidores de entrada-salida para cada disco permite que una
o mas operaciones de entrada-salida tengan lugar al mismo tiempo.
Si se ha alcanzado la máxima capacidad o escalabilidad, se puede
considerar la idea de cambiar la base a un sistema de partición
múltiple, descrito a continuación.
Distintas
Configuraciones de Particiones Múltiples
Además de los entornos antes mencionados, se puede dividir la base
de datos en particiones múltiples, cada una en su propia maquina.
Y además varias maquinas con particiones múltiples
de una base de datos pueden ser agrupadas.
Esta sección describe las siguientes configuraciones de particiones
posibles :
- Particiones en sistemas cada uno con un procesador.
- Particiones en sistemas cada uno con múltiples procesadores.
- Particiones lógicas de base de datos.
Una razón lógica para utilizar particiones lógicas
es la de brindar escalabilidad. El administrador de base de datos
múltiple que se ejecuta en particiones lógicas múltiples,
puede hacer un uso más completo de los recursos disponibles
que un administrador de una base simple de datos. Se gana mayor escalabilidad
sobre una maquina SMP mediante la adición de particiones, particularmente
en aquellas maquinas con varios procesadores.
Mediante la partición de la base de datos, se puede administrar
y recuperar cada partición por separado.
Nótese también que la habilidad de tener dos o mas particiones coexistiendo en la misma maquina ( sin importar el numero de procesadores) permite una mayor flexibilidad al diseñar configuraciones avanzadas de disponibilidad y estrategias para hacer frente a caídas del sistema.
Resumen
del Paralelismo mejor Adaptable a cada Entorno de Hardware
La
siguiente tabla resume los tipos de paralelismo que mejor se adaptan a
los diferentes entornos de hardware.
|
Entorno de Hardware
|
|
|
|
| Partición
Simple,
Único Procesador |
|
|
|
| Partición
Simple,
Múltiples Procesadores ( SMP ) |
|
|
|
| Particiones
Múltiples,
Un Procesador ( MPP ) |
|
|
|
| Particiones
Múltiples,
Múltiples Procesadores ( cúmulos de SMPs o cluster of SMPs ) |
|
|
|
| Particiones
Lógicas de Base de Datos
|
|
|
|
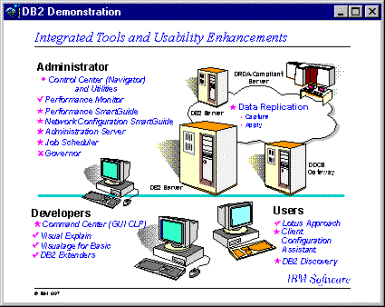
Herramientas
de Administración
DB2
Administración de Servidores
Asistente
para la Configuración de clientes
- Definir conexiones a base de datos de modo que éstas pueden ser utilizadas por aplicaciones. Existen 3 métodos:
- Examinar la red por base de datos disponibles y seleccionar una. El cliente automáticamente se configura para esa base de datos.
- Usar los perfiles de acceso a base de datos que provee el administrador para definir automáticamente las conexiones.
- Configuración manual de conexiones a base de datos para modificar algunos parámetros de conexión requeridos.
- Remover base de datos catalogadas o modificar sus propiedades.
- Testear la conexión con la base de datos identificada en su sistema para asegurarse que puede establecerse la conexión con el servidor que necesita.
- Enlazar aplicaciones a una base de datos seleccionando utilidades o enlazar archivos de una lista.
- Establecer conexiones con servidores DRDA si la conexión DB2 está instalada.

Administrador

El
administrador es usado para monitorear y cambiar el mejoramiento de aplicaciones
que corren a través de la base de datos.
Consiste en dos partes:
- Una utilidad de frente-final
- Un dominio
SmartGuides

Éstas son parte de las herramientas de administración de DB2 y nos guían a través de las tareas de administración. Las siguientes están habilitadas:
- Creación de base de datos: ayuda sobre la creación de base de datos, asignación de almacenamientos y selección de las opciones básicas más optimas. Para invocarla, chiquear sobre el icono de database en el Control Center y seleccionar Create-ànew.
- Creación de espacio de tablas: ayuda a crear nuevos espacios de tablas y configurar las opciones básicas de almacenamiento óptimo. Para invocarlo chiquear sobre el icono de Table Space en el Control Center, y seleccionar Create ->Table Space usando Smartguide.
- Creación de Tablas: ayuda a diseñar columnas (usando planillas de columnas pre-definidas si se desea), crear una clave primaria para la tabla y asignar la tabla a uno o más espacios. Para invocarla chiquear sobre el icono de Table en el Control Center y seleccionar Create ->Table usando Smartguide.
- Backup de Base de datos: hace preguntas básicas sobre la información de las bases de datos la disponibilidad de las bases de datos, las restricciones de baja horaria y requisitos de recuperabilidad. Esto sugiere un plan de backup, creación de scripts de trabajo y su schedules. Para invocarlo chiquear el icono que representa alguna de sus base de datos en el Control Center y seleccionar Backup -> database usando Smartguide.
- Recupero de base de datos: ayuda sobre el proceso de recuperación de base de datos. Para invocarlo chiquear sobre el icono que representa una de sus base de datos en el Control Center y seleccionar Backup -> database usando Smartguide.
- Optimización de la configuración: hace preguntas sobre la base de datos, su información y los propósitos del sistema y entonces sugiere nuevos parámetros de configuración para la base de datos y automáticamente las aplica a las base de datos si se desea. Para invocarlo chiquear en el icono que representa una de su base de datos en el Control Central y seleccione optimización de la configuración.
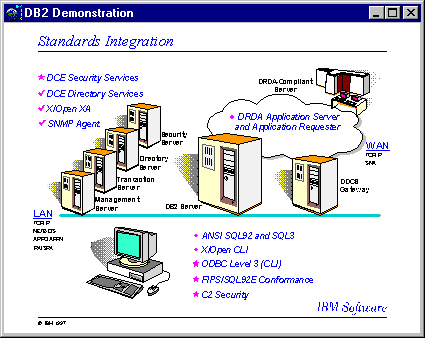
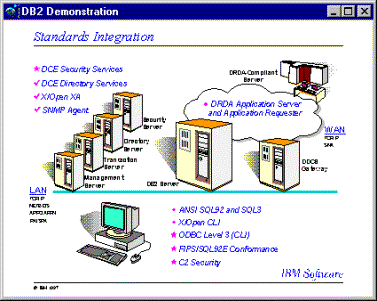
La UDB DB2 se adapta muy bien a los estándares industriales haciéndola muy integrable con otros productos IBM y también con aquellos que no lo son. La UDB DB2 soporta estándares API incluyendo ANSI SQL92E, Microsoft OBDC y JAVA/JDBC.
Con respecto a las aplicaciones de tipo cliente, se tienen procedimientos almacenados y funciones definidas por el usuario a través de VisualAge. Esto nos da una amplia elección de desarrollo de aplicaciones y herramientas finales para ser elegidas por los usuarios.
La
UDB DB2 también puede ser integrada con servicios de seguridad para
administrar servidores de nombre y direcciones. DB2 también soporta
SNMP y puede ser moni toreada desde cualquier Sistema de Administración
de Servers de IBM.
Para
poder establecer una comunicación con otras bases de datos relacionales,
la UDB DB2 soporta la Arquitectura de Base de Datos Relacional ( DRDA ).
Esta arquitectura también incluye el Servidor de Aplicaciones (
AS ) y gracias a ella DB2 puede correr sobre TCP/IP en forma
nativa, haciendo más fácil la implementación de un
entorno abierto de redes.
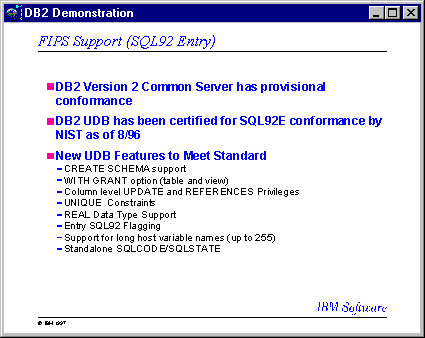
La
UDB DB2 también incluye las siguientes innovaciones en SQL, que
satisfacen los requerimientos:
SOPORTE
DE AUTORIZACION ADICIONAL
Las siguientes funciones han sido agregadas para soportar autorizaciones:
Privilegio
de ACTUALIZACION ( UPDATE ) del nivel de columna.
Privilegio de REFERENCIAS ( REFERENCES ) del nivel de columna.
Comando WITH GRANT OPTION en GRANT ( para tablas, vistas y columnas).
Privilegios
PUBLICOS ( PUBLIC ) para SQL estático y vistas.
SOPORTE
DE TIPOS DE DATOS REALES
Un
dato de precisión simple con coma flotante utilizando el comando
REAL es soportado por DB2.
DECLARACIONES
DE CREACION DE ESQUEMA ( CREATE SCHEMA ) Y ELIMINACION DE ESQUEMA ( DROP
SCHEMA )
Una
declaración de CREACION DE ESQUEMA ( CREATE SCHEMA ) y de
ELIMINACION DE ESQUEMA ( DROP SCHEMA ) son soportadas en DB2. Esto permite
tener privilegios asociados con
el control del esquema de la base de datos, en la cual los usuarios pueden
crear, alterar o eliminar objetos
del esquema.
SOPORTE
PARA RESTRICCIONES UNICAS
DB2 también soporta
restricciones únicas ( unique constraints ), las cuales se indican
a continuación :
Soporte
para uno o mas restricciones UNICAS sobre las tablas, en adición
a las CLAVES PRIMARIAS. -Las claves foráneas pueden referirse a
restricciones únicas.
El
chequeo de las restricciones únicas se realiza en diferido al finalizar
la declaración.
Los
nombres de las restricciones especificadas pueden ser utilizados como nombre
índices ( también aplicable a las claves primarias).
Las
RESTRICCIONES UNICAS y las CLAVES PRIMARIAS de tablas de partición
múltiple incluyen la
CLAVE DE PARTICION.
CONVERSION NUMERICA Y ARITMETICA AMIGABLE
Una
aritmética y conversión numérica amigable para asignar
variables, permite que una consulta sea llevada a cabo y proporcione algunos
resultados aunque los times de ciertos datos no hallan podido ser evaluados.
Esta función favorece la compatibilidad con ciertos sistemas como
ser OS/390.
Bibliografía

Soluciones
para un mundo pequeño
www.software.ibm.com/data/db2/udb
-
USING THE NEW DB2
IBM´s
Objest relational Database System.
Autor:
Don Chamberlin
-
![]()
- Si Ud. desea enviarnos algun comentario, sugerencia o simplemente necesita mas informacion , por favor hagalo clickeando la siguiente imagen :
- Pls. if you wish to contact us or you need
more information about DB2, double click on the next image :
Los logos de IBM, DB2, e-business y demas items
relacionados con la empresa IBM son marca registrada.
Solo se han utilizado en este sitio con fines
educativos y con el objeto de realizar una investigacion acerca del producto
DB2.
Los Autores.
IBM, DB2, e-business and any other relationed
topics with IBM, are registered trademarks.
They were placed in this web site ONLY for
educational and research pourposes about the DB2
product.
The Authors.